Thuyết trình giới thiệu PM Praat ứng dụng trong nghiên cứu ngữ âm thực nghiệm
 Ngày 25/10/2008 vừa qua, tại Khoa Ngôn ngữ học, Tiến sỹ Trần Đỗ Đạt - Giảng viên - Cán bộ nghiên cứu Trung tâm nghiên cứu quốc tế MICA, Đại học Bách khoa Hà Nội, UMI 2954 CNRS, đã trình bày về phần mềm Praat trong nghiên cứu ngữ âm thực nghiệm và một số kết quả đạt được khi áp dụng vào nghiên cứu tiếng Việt. Đến dự buổi thuyết trình có đông đảo giảng viên, NCS, HVCH và sinh viên của Khoa
Ngày 25/10/2008 vừa qua, tại Khoa Ngôn ngữ học, Tiến sỹ Trần Đỗ Đạt - Giảng viên - Cán bộ nghiên cứu Trung tâm nghiên cứu quốc tế MICA, Đại học Bách khoa Hà Nội, UMI 2954 CNRS, đã trình bày về phần mềm Praat trong nghiên cứu ngữ âm thực nghiệm và một số kết quả đạt được khi áp dụng vào nghiên cứu tiếng Việt. Đến dự buổi thuyết trình có đông đảo giảng viên, NCS, HVCH và sinh viên của Khoa
Thuyết trình giới thiệu phần mềm Praat trong nghiên cứu ngữ âm thực nghiệm

Ngày 25/10/2008 vừa qua, tại Khoa Ngôn ngữ học, Tiến sỹ Trần Đỗ Đạt - Giảng viên - Cán bộ nghiên cứu Trung tâm nghiên cứu quốc tế MICA, Đại học Bách khoa Hà Nội, UMI 2954 CNRS, đã trình bày về phần mềm Praat trong nghiên cứu ngữ âm thực nghiệm và một số kết quả đạt được khi áp dụng vào nghiên cứu tiếng Việt. Đến dự buổi thuyết trình có đông đảo giảng viên, NCS, HVCH và sinh viên của Khoa.
Mở đầu buổi thuyết trình, tiến sỹ Trần Đỗ Đạt nêu rõ những đặc tính ưu việt của phần mềm Praat so với các phần mềm xử lí tiếng nói khác như CoolEdit, SpeechAnalyser, Winsnorri, WinPitch. Đồng thời, cách sử dụng và các tính năng của Praat (như ghi âm, mở tệp tin, quan sát và hiệu chỉnh tín hiệu, phân tích tham số, phổ tín hiệu, phân tích cao độ, quan sát sự biến thiên của tần số cơ bản, thiết lập tham số, phân tích các tần số Phooc-măng (Formant), gán nhãn cho tín hiệu, trích chọn tham số, v.v.) cũng được tiến sỹ trình bày chi tiết và minh hoạ cụ thể.
Phần tiếp theo cũng quan trọng và lí thú không kém là những giới thiệu ban đầu về việc ứng dụng Praat cùng một số phần mềm bổ trợ khác trong nghiên cứu tiếng Việt như nghiên cứu thanh điệu, ngữ điệu và trường độ âm tiết tiếng Việt trong lời nói liên tục.
Tiến sỹ Trần Đỗ Đạt là một thành viên trong nhóm nghiên cứu TIM của trung tâm MICA với mục tiêu chính là xây dựng một nhóm nghiên cứu có trình độ chuyên môn cao trong lĩnh vực xử lý tiếng nói. Nhóm nghiên cứu này có nhiệm vụ thực hiện nghiên cứu về các đặc trưng của ngôn ngữ cho các tiếng khác nhau như tiếng Việt, tiếng Pháp, tiếng Campuchia.., đồng thời triển khai xây dựng những hệ thống tương tác người máy bằng tiếng nói cho tiếng bao gồm hệ thống tổng hợp tiếng nói từ văn bản và hệ thống nhận dạng tiếng nói tự động.
Ở các nước phương Tây, các nghiên cứu này được tiến hành từ những năm 70 của thế kỷ 20, tuy nhiên ở Việt Nam vấn đề này mới chỉ bắt đầu được đầu tư trong những năm gần đây trong đó nghiên cứu ngôn ngữ tiếng Việt theo phương diện xử lý tín hiệu và âm học thì còn rất yếu. Những thuật toán tổng hợp hay nhận dạng tiếng nói đã từng được ứng dụng vào các ngôn ngữ phương Tây sẽ không thể áp dụng trực tiếp vào tiếng Việt. Việc tìm ra được các thuật toán hiệu quả nhất đối với tiếng Việt thực sự cần sự “chung sức chung lòng” của các nhà nghiên cứu ngôn ngữ và công nghệ thông tin.
Dưới đây là một vài hình ảnh về hệ thống tổng hợp tiếng Việt phục vụ cho mục dích nghiên cứu đang được xây dựng của Trung tâm nghiên cứu quốc tế MICA.
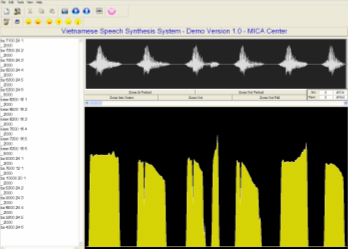
Tổng hợp các âm tiết của tiếng Việt với 6 thanh điệu khác nhau
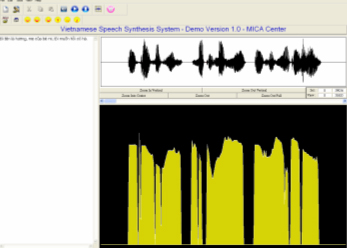
Tổng hợp một câu nói hoàn chỉnh của tiếng Việt
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
- Đang truy cập15
- Hôm nay592
- Tháng hiện tại592
- Tổng lượt truy cập5,656,186